
PeiLingX
物理学等 2 个话题下的优秀答主
本文是深度科普系列《从线性代数到量子力学》的第17课。
本系列及本专栏其他文章,建议收藏目录:
0) 开篇语
在第16课的开头我们提到,比起一维模型来,三维模型蕴含着更丰富的物理内涵和一维模型所不具有的对称性,而这其中最典型的就是氢原子,因此我们也在第16课先简单回顾了一下前量子时代氢原子问题的一些往事。
接下来的旅程中,我们就要真正用量子力学的方式,去求解氢原子模型的薛定谔方程,并且通过它的解来了解氢原子光谱的更多离奇性质。
不过,由于氢原子问题通常是放到球坐标中求解的,而球坐标系的坐标表象下的哈密顿算符、以及能量本征态的函数形式,对我们来说都还有点陌生。
因此,我们这节课还是先在直角坐标中熟悉一下三维模型的一些共同特点,然后再在下节课中讨论球坐标。
我们先从最简单的坐标和动量算符的三维情形说起。
1) 三维坐标和动量算符
经典力学中,当给定了坐标系时,我们可以用位矢:
x=x→i+y→j+z→k(式17.1)
以及动量:
p=px→i+py→j+pz→k(式17.2)
来描述一个运动物体某时刻的运动状态。
(其中→i,→j,→k是三个坐标基底,上面加上箭头是为了将x方向的基底→i和虚数单位i区分开来)
而在量子力学中,我们将坐标和动量分别换成了算符ˆx和ˆp,并且通过本征值和经典力学量联系起来。
但以前我们主要讨论的是一维模型,三维模型中的算符又该如何同经典力学中的力学量联系起来呢?
这个其实很简单,用一句话概括就是“分别求本征值”。
以动量为例,我们可以将动量算符也拆成三个分量的算符,并且分别作用在态矢量上。
形式上写出来就是:
ˆp=ˆpx→i+ˆpy→j+ˆpz→k(式17.3)
ˆp|ψ⟩=(ˆpx→i+ˆpy→j+ˆpz→k)|ψ⟩ =ˆpx→i|ψ⟩+ˆpy→j|ψ⟩+ˆpz→k|ψ⟩(式17.4)
当然,这么写看起来其实有点抽象,但是如果我们考虑这个算符作用在动量本征态上的结果,就能找到点感觉了。
如果一个粒子动量的三个分量可以同时确定(或者更规范地说,如果它们相互对易),那么它们将具有一组完备的共同本征态,将其中某个共同本征态记为|Pabc⟩,并且假设三个分量分别有本征值关系:
{ˆpx|Pabc⟩=pa|Pabc⟩ˆpy|Pabc⟩=pb|Pabc⟩ˆpz|Pabc⟩=pc|Pabc⟩(式17.5)
那么很显然的是,三维的动量算符ˆp作用在|Pabc⟩上面,可以分别得到三个分量的本征值,将它们组合起来,就是经典力学中可以观测到的三维动量的三个分量ˆpx→i+ˆpy→j+ˆpz→k
写成本征值关系式就是:
ˆp|Pabc⟩=(ˆpx→i+ˆpy→j+ˆpz→k)|Pabc⟩=ˆpx→i|Pabc⟩+ˆpy→j|abc⟩+ˆpz→k|abc⟩=pa→i|Pabc⟩+pb→j|abc⟩+pc→k|abc⟩=(pa→i+pb→j+pc→k)|Pabc⟩(式17.6)
(在第二个等号到第三个等号之间的计算中,三个基底→i,→j,→k只是作为基底符号存在,可以看作常系数,因此并不影响算符对态的作用)
不过话说到这里,我们需要明确一个前提:三个方向上的动量真的可以同时确定吗?
答案是肯定的。我们本系列会用三种方式去得出它。
第一种是直接的数学方式:我们可以写出坐标表象下动量算符的形式,也就是对三个坐标的偏微分:
{ˆpx→−iℏ∂∂xˆpy→−iℏ∂∂yˆpz→−iℏ∂∂z(式17.7)
而我们知道,偏微分是可以交换求导顺序的,这就意味着三个方向上的动量算符相互对易,回想我们在第14课中提到过的概念:两个相互对易的算符具有共同的本征态,也就是可以同时具有确定的值,我们就能得出三个方向上可以同时具有确定动量的结论。
不过,这个方式数学味道太过纯粹,少了一点具体的物理图像,所以我们重点来看看第二种方式,从纯粹物理的层面去理解和推导。
首先,我们考虑一个沿x方向的一维模型:
一个处于动量本征态|pa⟩的粒子,对应着动量本征值pa,于是它就有着沿x方向的确定的动量值。
现在,我们给这个模型加上另外两个坐标轴y,z,我们看到,这只是数学上的描述从一维变成了三维而已,物理上没有任何实质性的改变,粒子仍然具有确定的沿x方向的动量值pa
现在,我们将原来的xyz坐标系随便绕某个轴旋转某个角度,得到新的坐标系x′y′z′,那么显然,在新的坐标系中,粒子的动量不再沿x′方向,而是会在三个坐标轴上都有投影。
但此时我们仍然只是进行了数学上的基底变换,物理上还是没有任何实质性的改变,粒子仍然具有沿着某个方向上的确定的动量,而这个动量投影到三个新的坐标轴上,就变成了三个确定的分量p′a,p′b,p′c
这也就意味着三个方向上的动量分量值可以同时确定。
最后我们再简单说说第三种方式,这种方式更具有几何味道,虽然我们现在还不能理解,但可以先留个印象:
量子力学中,动量算符可以被看作坐标平移群的生成元,而不同方向的坐标平移具有可交换性(在平面上,“先向东走100米再向北走100米”和“先向北走100米再向东走100米”,最后都能到达同一个地方),这意味着不同方向的动量算符也可以交换顺序,也就是它们相互对易、具有共同本征态。
当然,现在我们还不用急着去了解什么是坐标平移群、什么是生成元,以后我们还会专门介绍,现在我们只需要模糊地知道、平移这个几何操作和动量算符之间有着微妙的关系就行了。
(想提前被剧透的同学,可以去翻翻樱井纯先生那本著名的书[1])
除了动量以外,对于坐标,我们也可以类比着给出相同的结论:
三个方向上的坐标也是可以同时确定的,具有共同的本征态,并且有本征值关系:
ˆx|Xabc⟩=(xa→i+yb→j+zc→k)|Xabc⟩(式17.8)
到此为止,我们所做的全部事情,看起来就是将以前讨论的一维模型简单推广到了三维情形而已,似乎也没有什么新的东西。
但实际上,三维模型中会出现很多一维模型无法得出的新的性质,比如我们接下来要讨论的能量的简并。
2) 能量的简并
我们先用一个物理意义简单明了的例子,来看看什么是能量的简并。
考虑势能处处为0的空间中的一个自由粒子,它的总能量即是动能,于是哈密顿算符为:
ˆH=ˆp22m=ˆp2x+ˆp2y+ˆp2z2m(式17.9)
现在假设这个粒子有两个动量本征态,它们在坐标表象下的波函数为:
|P1⟩=Aexp[i(kx)]|P2⟩=Aexp[i(k√3x+k√3y+k√3z)](式17.10)
对于|P1⟩而言,动量本征值关系为:
ˆp|P1⟩=−iℏ(∂∂x→i+∂∂y→j+∂∂z→k)Aexp[i(kx)]=(ℏk→i+0→j+0→k)Aexp[i(kx)]=(ℏk→i+0→j+0→k)|P1⟩(式17.11)
于是动量本征值为:
p1=ℏk→i+0→j+0→k(式17.12)
同理,对于|P2⟩而言,可以算出动量本征值为:
p2=ℏk√3→i+ℏk√3→j+ℏk√3→k(式17.13)
我们看到,两个态具有不同的动量本征值,因此它们明显是两个不同的本征态。
而我们在第9课曾经提到过,对于自由粒子而言,由于没有(与坐标有关的)势能函数存在,所以能量和动量算符具有共同的本征态。于是,上面提到的两个动量本征态同时也是能量的本征态。
现在我们来看它们对应的能量本征值。
如果将三维动量算符看成是一个由算符组成的三维矢量,那么三维模型中自由粒子的哈密顿算符就是动量算符的内积,即:
ˆH=ˆp2x+ˆp2y+ˆp2z2m(式17.14)
再放到坐标表象下面,就是梯度算子与自己做内积:
ˆH=−ℏ22m(∂2∂x2+∂2∂y2+∂2∂z2)(式17.15)
现在,将它作用到前面给出的两个动量本征态(对于自由粒子而言同时也是能量本征态)上面,那么我们不难算出:
{ˆH|P1⟩=ℏ2k22m|P1⟩ˆH|P2⟩=ℏ2k22m|P2⟩(式17.16)
也就是两个不同的能量本征态 |P1⟩,|P2⟩具有相同的能量本征值 E=ℏ2k22m
这种同一个能量本征值对应多个能量本征态的情形,我们就统称为能量的简并(Degenerate),相应的本征态的个数称为简并度。
(当然,简并的概念也可以推广到其他算符上,这个我们以后还会讨论,现在我们还是主要关注能量的简并)
显然,在我们这个自由粒子的例子中,只要三个动量本征值分量满足:
p2x+p2y+p2z=ℏ2k2(式17.17)
(可以看作动量空间的 “球面”)
则相应的本征态都是能量本征值E=−ℏ2k22m的简并态,相应的简并度就是无穷大。
不过,对于讨论简并而言,自由粒子其实并不是一个很值得深究的案例,我们之所以先介绍它,是因为它有着非常明确的经典对应:经典力学中,大小相同而方向不同的动量,对应的是同一个动能。这将有助于我们先对简并的概念建立一个直观印象。
而更值得我们深究的,是处于势能束缚中的粒子。
那么束缚态是否也可能存在能量简并的情形呢?
答案是肯定的,在我们稍后要给出的一个例子、以及未来将要讨论的氢原子模型中,都会看到这一点。
而回想我们在第10课中提到过,处于束缚态的粒子,能量本征值往往都是分立能级,于是对应着多个本征态的同一个能级就被称作简并能级。
在束缚态下,能级的简并是只在二维及更高维度的量子力学模型中才会出现的好玩性质[2],它可以解释很多经典物理(包括玻尔的半经典模型)所不能解释的奇特现象(比如我们上节课末尾提到的各种能级分裂效应),还蕴含着一些美妙的对称性。
我们马上就来找一个简单的例子、简单地感受一下。
3) 能级简并与分裂:一个简单例子
在第10课中,我们曾经讨论过一个最简单的一维模型:一维无限深势阱。
它描画了一个被严格限制在区间(0,L)内的自由粒子(我们可以想象一个被困在一段长为L的导线内的电子),我们通过求解区间内的薛定谔方程、并且以“粒子出现在区间边界的概率为0”作为边界条件,求出了能量本征值和能量本征态序列:
En=n2π2ℏ22mL2(式10.18)
ψn(x)=√2Lsin(nπLx)(式10.25)
现在,我们将这个模型推广到三维,考虑一个长宽高为L×L×L的正方体无限深势阱,正方体区域内势能为0,区域外势能为无穷大。
我们这里直接给出能级和能量本征函数解,省略这个模型的求解过程,因为这组解看起来非常理所当然、以至于我们会产生“不需要求解过程”的错觉。
怎么个理所当然法呢?它和一维模型相比,形式上几乎没有变化,仅仅是简单加上或乘上了另外两个维度的解而已:
{Enxnynz=(n2x+n2y+n2z)π2ℏ22mL2(nx,ny,nz=1,2,3,⋯)ψnxnynz=(√2L)3sin(nxπLx)sin(nyπLy)sin(nzπLz)(式17.18)
这里我们看到,能量本征值和本征态都与3个整数nx,ny,nz有关,它们分别对应3个坐标方向上“驻波”的波数,我们也将它们称作“量子数”。
利用这三个量子数,我们可以将能量本征函数(也就是本征态的坐标表象)抽象地表示为狄拉克符号:
ψnxnynz→|nxnynz⟩(式17.19)
现在,我们来看看能级简并的问题。
在一维无限深势阱模型中,描述本征态只需要一个量子数n,而不同的n对应着不同的能量本征值,因此没有简并能级存在。
而到了三维模型,我们很容易发现,能级是三个量子数的平方和,只要三个量子数互不相等,我们就有可以通过对它们进行不同排列凑出一个简并能级。
一个非常简单的情况就是这6种本征态:
{|nxnynz⟩=|123⟩|nxnynz⟩=|231⟩|nxnynz⟩=|312⟩|nxnynz⟩=|321⟩|nxnynz⟩=|213⟩|nxnynz⟩=|132⟩(式17.20)
它们对应的能量本征值都是:
E123=E231=E312=E321=E213=E132=14E0(E0=π2ℏ22mL2)(式17.21)
也就是说,同一个能量值E=14E0对应着6个不同的本征态,相应的简并度为6.
上面的组合还只是同一组数字的不同排列,有时候我们还会遇到不同的数字组合得到同样的平方和,这时候就会带来更高的简并度,比如对于E=38E0这个能级,相应的本征态有:
|116⟩,|161⟩,|611⟩,|235⟩,|352⟩,|523⟩,|532⟩,|325⟩,|253⟩
一共9个本征态,也就是能级E=38E0的简并度为9.
我们还可以看到,随着能级的升高,可能出现的简并度也越高,下图是能量值从E=3E0到E=2500E0之间的各个能级的简并度分布(代码在文末),同学们可以感受一下:
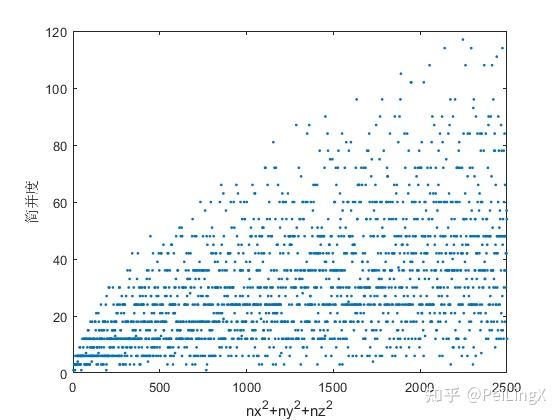
不过,上面这个例子有一个非常特殊的特点是,势阱是一个正方体。现在我们要来看看,如果让势阱变成一个一般的长方体,能级简并是否还存在。
为了让问题更有一般性,我们不妨假设势阱三个方向的长度平方之间不存在任何有理数倍数关系(也就是任意一个长度的平方不能表示成其他两个长度平方的有理数倍);
另外,为了和今后要介绍的微扰论相联系,也为了更好地“看到”能级的分裂,我们假设,新的长方体的长宽高,与正方体相比只变化了很小的量。
基于以上两个假设,我们不妨给出这样一组长宽高:
(Lx,Ly,Lz)=(L, (1+π1000)L, (1−π1000)L)(式17.22)
在这个模型下,薛定谔方程的解为:
{Enxnynz=(n2x+10002(1000+π)2n2y+10002(1000−π)2n2z)π2ℏ22mL2|nxnynz⟩=Asin(nxπLx)sin(1000ny(1000+π)Ly)sin(1000nzπ(1000−π)Lz)(A=√2L√2000(1000+π)L√2000(1000−π)L)(式17.23)
可以证明,这样的情形下,我们找不到任何两组不同的整数组合nx,ny,nz和n′x,n′y,n′z来满足:
n2x+10002(1000+π)2n2y+10002(1000−π)2n2z=n′x2+10002(1000+π)2n′y2+10002(1000−π)2n′z2(式17.24)
也就是说,这个时候就没有简并态存在了。
为了直观感受这一点,我们还是以123的数字组合为例,然后我们会发现,长方体势阱模型中,nx,ny,nz取数字123的不同排列,将得到不同的能量本征值:
{E123=14.03E0E231=13.95E0E312=14.02E0E321=13.98E0E213=14.05E0E132=13.97E0(式17.25)
实际上,如果我们将例中的长方体模型看成是正方体模型的基础上加上了大约千分之三的微小的势能扰动后的结果,那么物理直观上看起来,就像是这个微小的扰动使得原来正方体模型的能级14E0分裂成了6个不同的能级(如下图)
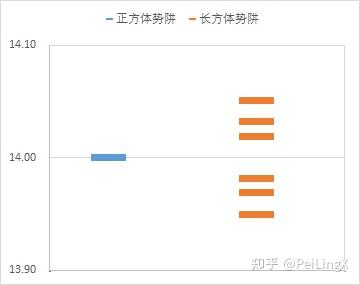
假如这个粒子的状态也会在不同能级之间跃迁,那么在正方体势阱模型中,一个粒子从14E0 跃迁到其他能级、比如E111=3E0时,就会放出一个频率为11E0h的光子,然后我们就会在光谱上相应位置发现一条特征谱线。
而加上微小扰动变成长方体势阱后,粒子就有可能从分裂出来的6个能级跃迁到E111,但每条谱线的频率和正方体模型的单根谱线频率也就相差千分之几,那么看起来就像正方体模型的那条谱线附近发生了细微的分裂一样。
当然,无限深势阱只是一个理想化的模型,而我们以后将要讨论的真实的模型是氢原子,但它本质上和无限深势阱模型没有太大差别,只是计算会更复杂一些、物理意义也会更精妙一些。
另外,通过上面两个例子,我们还可以先定性地感受一下简并和对称性的关系:
我们知道,正方体比长方体具有“更好的”对称性,当正方体势阱变成长方体的时候,对称性被破坏,相应的简并能级也被破坏了。
不过,如果要更深刻地讨论对称性和简并之间的关系,方势阱也并不是一个特别好的例子。更精妙的对称性还是要在以氢原子为典型的球对称势中去寻找(毕竟,球比正方体更对称),到时候我们还会从数学上更准确地去理解它,这是我们未来的课程中非常值得期待的一件事情。
这里顺便再说一句,我们知道,真实物理世界中其实并不存在理想的无限深势阱,也不存在理想的正方体,因此无限深势阱模型中那种严格意义上的简并其实也只是一种理想情形。
但通过前面的例子我们看到,当真实模型和理想正方体相差不太远时,分裂出来的能级也会在理想模型的简并能级附近,并且能级的变化量和扰动的变化量在某种近似下可以认为是线性关系。
当真实模型与理想模型偏离足够小时,我们也可以在一定误差范围E+dE内忽略能级的分裂,将它近似看做简并的。这其实和原子光谱也能对应上:原子光谱的每一条谱线其实都是有一定宽度的(否则我们也不容易观察到),这就是因为原子的简并能级在实际物理环境中各种微小的外场扰动下发生了不同程度的分裂,这些分裂很微小又各不相同,最后重叠在一起,就形成了有一定宽度的谱线,但我们仍然可以近似认为它们就是同一条。
现在我们还是回到关于简并的讨论本身,来完成这节课的最后一个话题:
前面我们从求解微分方程的角度体验了能级的简并以及分裂,现在,我们要切换到线性代数的角度,先粗略地体会一下,能级简并以及分裂在代数上对应着什么。
4) 简并的线性代数对应
同学们大概已经看出来了,从简并的定义看,相同本征值对应着不同本征态,其实就类似于线性代数中具有不同特征向量的多重特征值的情况。
我们不妨考虑一种最简单的情形,比如某个矩阵A是一个单位矩阵的常数倍,即:
A=aI(式17.26)
那么它的特征值就只有一个a,对应到物理中,也就相当于有一个本征值为a的“简并能级”。
当我们给A加上另一个矩阵B的时候,很容易验证,A+B的特征值就是{a+λB,n} (其中{λB,n}是矩阵B的特征值序列,见文末附录2)
如果{λB,n}序列中的特征值互不相等,那么对应到能级的简并和分裂上,就相当于是原来的简并能级a分裂成了不同的{a+λB,n}
此外,如果我们考察这个过程中特征向量的变化,也会发现一些更有意思的事情:
在没有加上矩阵B的时候,A=aI的特征向量可以是任意单位向量,但是一旦变成了A+B,我们不难知道,这个新矩阵的特征向量就具有了特殊性,只能取矩阵B的特征向量(证明很简单,留做练习,见文末附录2)。
这其实就相当于,原本可以在球对称的空间中任取一组方向作为特征向量的情形,变成了只能取一组特殊方向的情形。
从球对称的任意方向到不具对称性的特殊方向,显然是一种对称性的破坏,因此,我们在这里又一次隐约感受到了简并的解除与对称性的破坏之间的关系,而这个结果将有助于我们以后理解氢原子问题解的球对称性。
当然,实际的物理情形中,并不是所有的能级都等于同一个值,所以,上面给出的“常数乘以单位矩阵”这种简单形式,并不具备真实的物理意义,只是帮助我们从代数角度简单感受一下能级分裂以及它与对称性破坏的关系而已。
而要计算实际物理情形中的能量本征值变化、特别是外加的能量扰动比较小时,我们会用到一种名叫微扰法(Perturbation Method)的近似方法来处理,这个我们留到将来介绍氢原子能级分裂的时候再来介绍。
5) 小结与预告
这节课里,我们从坐标和动量算符入手,简单介绍了三维空间中的量子力学,并且通过三维无限深势阱模型的解,感受了多维束缚态问题不同于一维问题的一个特有性质:能级的简并。
然后,我们又通过改变势能的分布,简单感受了简并的解除、能级的分裂、以及与之相伴的对称性的破坏。
当然,我们引入这个模型只是因为它足够简单,可以帮助我们先对三维世界的特点建立一个初步印象。但更适合描述氢原子问题的是球坐标。所以接下来,我们就要来为理解氢原子问题做一些准备:在球坐标系中讨论各类力学量算符以及它们之间的关系。
附录1:简并度的计算代码
代码用的Matlab,很简单:
n=0;
MaxNum=50;
%↓以下生成nx^2+ny^2+nz^2平方和序列
for nx=1:MaxNum
for ny=1:MaxNum
for nz=1:MaxNum
n=n+1;
S(n,1)=nx;
S(n,2)=ny;
S(n,3)=nz;
S(n,4)=nx^2+ny^2+nz^2;
end
end
end
%S里面包含了不同nx,ny,nz组合的信息
T=S(:,4);%单独读取平方和列表
[U,Idx]=sort(T);%平方和从小到大排序
A=unique(U);% 平方和去除重复值
%↓以下计算简并度
for m=1:length(A)
if A(m)<(MaxNum+1)^2+2
B(m,1)=A(m);%平方和的值赋给B的第1列
B(m,2)=sum(T(:)==A(m));%简并度赋给B的第2列
end
end
X=B(:,1);%横轴:nx^2+ny^2+nz^2
Y=B(:,2);%纵轴:简并度
plot(X,Y,'.');附录2:一道简单的课后练习
设矩阵 A=aI ,其中a为常数,I为单位矩阵;设矩阵B可逆,且具有互不相等的特征值序列 {λB,n},相应的特征向量记为{βn}
求证:A+B的特征值为{a+λB,n},相应的特征向量为{βn}
参考
J. J. Sakurai (樱井纯),《现代量子力学(第二版)》,中译本(丁亦兵等 译),第32~36页
也就是说,任意一个一维束缚态模型都没有简并能级存在,相关证明可以参考顾樵先生的《量子力学 卷1》第94页。而一维的自由粒子还是有简并态存在的,我们只需要考虑一个动量本征值为p的状态和动量本征值为−p的状态就明白了
编辑于 2021-12-20 13:40